Topology Service: On-Call Survival Guide
This guide helps on-call engineers respond to Topology Service incidents. It assumes you’re familiar with SLIs, error budgets, and cloud platforms (GCP), but have no prior knowledge of Topology Service.
What is Topology Service?
Section titled “What is Topology Service?”Topology Service is the central coordination system for GitLab Cells, providing three critical services that enable routing, global uniqueness, and cell provisioning. It runs in two deployment modes: REST API (topology-rest) for HTTP Router and gRPC API (topology-grpc) for internal cell operations. It is deployed from topology-service-deployer and is deployed via Runway. Runway itself orchestrates the deployments via ‘deployment projects’ (topology-rest & topology-grpc)
Three Core Services & Failure Impacts
Section titled “Three Core Services & Failure Impacts”| Service | Purpose | Code Path | Deployment | Impact When Down |
|---|---|---|---|---|
| ClassifyService | REST (Routes requests to correct cell) | internal/services/classify/ | REST | CRITICAL: All routing broken, no requests reach cells1 |
| ClaimService | Ensures global uniqueness (usernames, emails, namespaces) | internal/services/claim/ | gRPC only | Cannot create users/groups/projects, transactions fail |
| SequenceService | Allocates non-overlapping ID ranges during cell provisioning | internal/services/cell/ | gRPC only | Cannot provision new cells |
Footnotes: [1] ClassifyService failure is gradual - routing degrades as cache expires. Indicators: decreased (not zero) cell-local traffic, 404 spike from legacy cell fallback.
Key takeaway for on-call: ClassifyService affects routing (immediate user impact), ClaimService affects writes (no routing impact but increases database transaction failure), SequenceService affects only new cell provisioning.
Critical dependency: All services rely on Cloud Spanner. Spanner CPU/connection issues cascade to all three services.
Architecture in Brief:
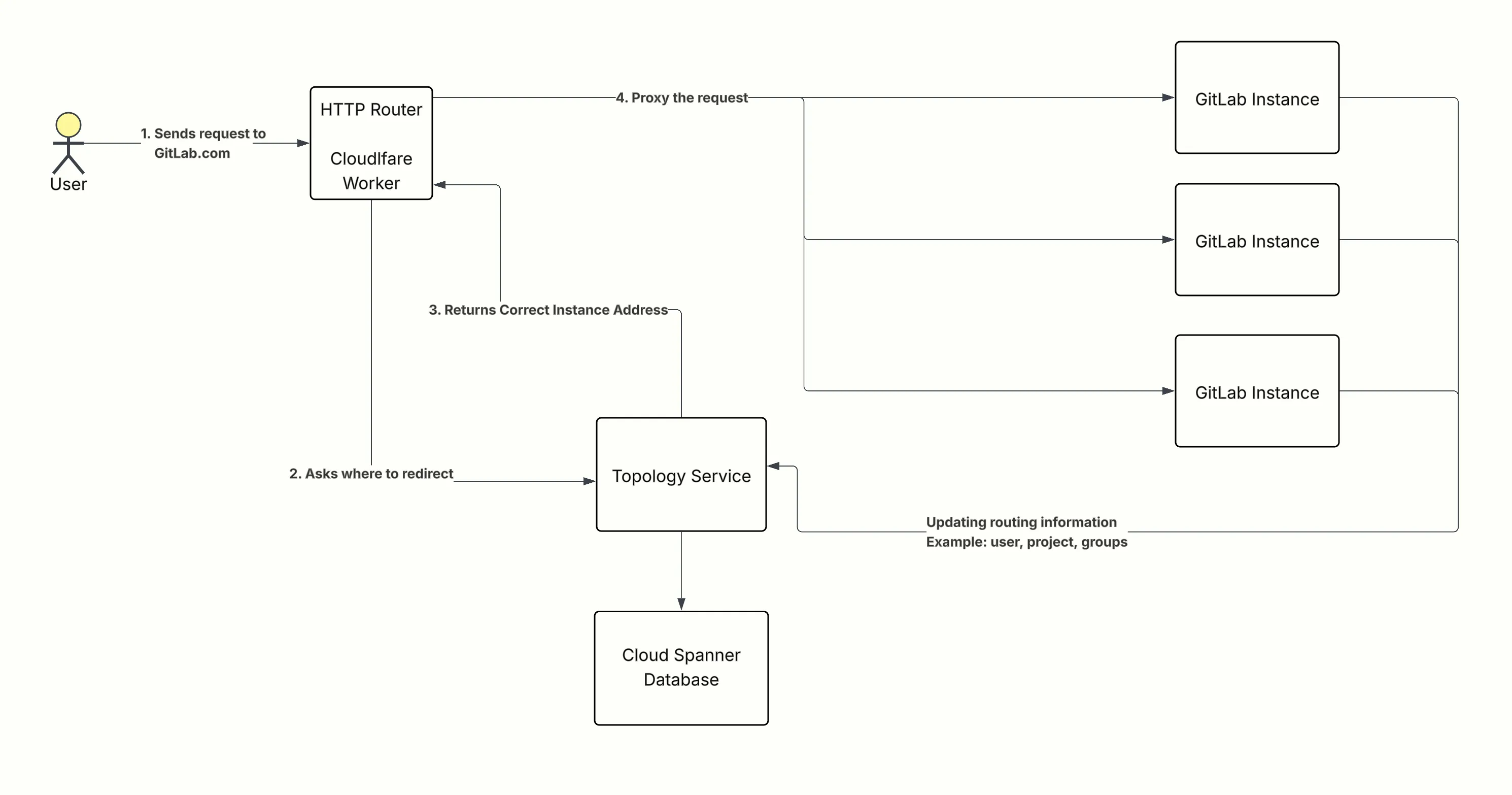
Topology Service design: https://handbook.gitlab.com/handbook/engineering/architecture/design-documents/cells/topology_service/
Quick Reference Card
Section titled “Quick Reference Card”Key Resources
Section titled “Key Resources”- Dashboards: gRPC Prod | REST Prod | Spanner Prod | RBAC Auth
- Deployment: topology-service-deployer
- Source: topology-service
- Cloud Run: Production Console
- Spanner: Production Console
- Runway Deployment Projects: topology-grpc , topology-rest , topology-migrate
- Logs: Grafana Logs [REST], Grafana Logs [GRPC], Cloud Logging Spanner
Emergency Access
Section titled “Emergency Access”For infrastructure-level troubleshooting, Cloud Spanner logs, or emergency rollbacks via Cloud Run UI, you’ll need Breakglass access to the GCP Console:
- Cloud Logging for Cloud Spanner
- Cloud Run Console for container-level operations
GCP Console (UI):
- Production PAM
- Click “Request Access” → Select
breakglass-entitlement-gitlab-runway-topo-svc-prod→ Enter incident link → Submit
gcloud CLI (Breakglass):
# Productiongcloud beta pam grants create \ --entitlement="breakglass-entitlement-gitlab-runway-topo-svc-prod" \ --requested-duration="1800s" \ --justification="$INCIDENT_LINK" \ --location=global \ --project="gitlab-runway-topo-svc-prod"Emergency Contacts
Section titled “Emergency Contacts”- Topology Service + Spanner:
Cells - Immediate help:
#g_cells_infrastructure - Business hours:
#f_protocells
Component Overview & Common Failures
Section titled “Component Overview & Common Failures”| Component | What It Does | Dashboard | Logs |
|---|---|---|---|
| REST API (topology-rest) | HTTP endpoint for HTTP Router to classify requests | REST Dashboard | Grafana Logs & Cloud Run Logs |
| gRPC API (topology-grpc) | Internal API for cells: claim resources, classify, manage ID sequences | gRPC Dashboard | Grafana Logs & Cloud Run Logs |
| Cloud Spanner | Stores classifications, claims, ID sequences | Spanner Dashboard | Cloud Logging |
Alert Types & Response
Section titled “Alert Types & Response”| Alert | Think | Check |
|---|---|---|
| ApdexSLOViolation (gRPC/REST) | Requests too slow or failing | Spanner → Service Service Panel → Spanner Service Logs |
| ErrorSLOViolation (gRPC/REST) | Service returning errors | Service logs → Spanner status → Recent deployments |
| TrafficCessation (gRPC/REST) | No traffic (was flowing 1hr ago) | Cloud Run instances → Deployment pipeline |
| Regional (suffix) | Single region problem | Same as above, region-specific |
| AuthRequestsApdexSLOViolation | mTLS auth taking too long | Check cert chain complexity → policy evaluation overhead → RBAC Auth Dashboard |
| AuthRequestsErrorSLOViolation | mTLS auth failures elevated | Check cert validity/expiry → RBAC policies → recent deployments → auth_requests_total{status="failure"} by reason label |
Mental models:
- High latency? Example: think Spanner CPU → Spanner resource limits → Network
- Errors? Example: think Spanner connection → Service crash → Bad deployment
- No traffic? Example: think Instances down → Load balancer → Deployment
- Post-deployment weirdness? Check: Recent deployments → Service logs → Spanner status
Deployment Procedures
Section titled “Deployment Procedures”Never rollback. Always roll forward. Spanner schema migrations are one-way only.
Why We Roll Forward Only Topology Service uses a dual-codebase deployment pattern and Cloud Spanner schema migrations. Rolling back code risks:
(1) deployment/application version mismatches causing failed deploys.
(2) schema incompatibility causing startup failures or database corruption during the zero-instance deployment window.
To recover safely in the event of an incident and a code change is suspected as the root cause:
- Create a revert, branch from known-good code, rebase onto main, add forward-compatible schema changes if needed, then deploy normally. Asking for approvals normally.
- Transient failures: Retry pipeline stage in topology-service-deployer
- Code issues: Push fix via MR to topology-service or deployer
- Critical bugs: Revert commit in Git, deploy the revert
Metrics Quick Reference
Section titled “Metrics Quick Reference”Two independent metric paths:
-
Application:
{job="topology-service", type="topology-[grpc|rest]", environment="gprd"}- Business logic, gRPC method stats -
Infrastructure:
{job="runway-exporter", project_id="gitlab-runway-topo-svc-prod"}- Cloud Run CPU/memory, Spanner metrics -
RBAC Authentication:
{job="topology-service", type="topology-grpc"}— mTLS auth metrics (gRPC only)auth_requests_total{status, reason, rpc_method, rpc_service}— auth success/failure countspolicy_failures_total{reason, rpc_method, rpc_service}— RBAC policy violationsauth_request_duration_seconds_bucket{rpc_method, rpc_service}— auth latency histogram- RBAC Auth Dashboard
Query via Grafana Explore (mimir-runway datasource).
Remember
Section titled “Remember”- Access expires: Please remember that PAM grants do have a duration
- Document everything: Add findings to incident timeline
- Escalate early: Team prefers early escalation over solo struggle
- Roll forward, never rollback: Always deploy fixes via new commits
- When in doubt: Ask in #g_cells_infrastructure or #f_protocells