Provisioning a new shard
Access requirements
Section titled “Access requirements”- GPRD admin account access
- Chef server admin
- Write access in repos:
Quota Increases
Section titled “Quota Increases”- Reach out to Google reps in
#ext-google-cloudSlack channel.- NOTE: Do this as early as possible in the process, as soon as we have an idea of many resources we’ll need, even before the projects exist. Do not assume we will have auto-approval on anything.
- Collaborate with GCP reps on provisioning and due dates.
- Submit standard quota increase requests in the GCP console.
:warning: If you need to increase quotas for Heavy-weight read requests per minute, it is possible you need to specifically increase Heavy-weight read requests per minute per region as seen in this issue.
Typically, the following quotas will need to be increased:
- N2D CPUs (us-east1)
- Read requests per minute per region (us-east1)
- Heavy-weight read requests per minute per region (us-east1)
- Queries per minute per region (us-east1)
- Concurrent regional operations per project per operation type (us-east1)
Compare the settings with other existing projects and request needed adjustments.
https://console.cloud.google.com/iam-admin/quotas?project=gitlab-r-saas-l-m-amd64-org-1&walkthrough_id=bigquery--bigquery_quota_request&pageState=(%22allQuotasTable%22:(%22f%22:%22%255B%257B_22k_22_3A_22Name_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22N2D%2520CPUs_5C_22_22_2C_22s_22_3Atrue_2C_22i_22_3A_22displayName_22%257D_2C%257B_22k_22_3A_22_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22OR_5C_22_22_2C_22o_22_3Atrue%257D_2C%257B_22k_22_3A_22Name_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22Heavy-weight%2520read%2520requests%2520per%2520minute%2520per%2520region_5C_22_22_2C_22s_22_3Atrue_2C_22i_22_3A_22displayName_22%257D_2C%257B_22k_22_3A_22_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22OR_5C_22_22_2C_22o_22_3Atrue%257D_2C%257B_22k_22_3A_22Name_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22Read%2520requests%2520per%2520minute%2520per%2520region_5C_22_22_2C_22s_22_3Atrue_2C_22i_22_3A_22displayName_22%257D_2C%257B_22k_22_3A_22_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22OR_5C_22_22_2C_22o_22_3Atrue%257D_2C%257B_22k_22_3A_22Name_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22Queries%2520per%2520minute%2520per%2520region_5C_22_22_2C_22i_22_3A_22displayName_22%257D_2C%257B_22k_22_3A_22_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22OR_5C_22_22_2C_22o_22_3Atrue%257D_2C%257B_22k_22_3A_22Name_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22In-use%2520IP%2520addresses_5C_22_22_2C_22i_22_3A_22displayName_22%257D_2C%257B_22k_22_3A_22_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22OR_5C_22_22_2C_22o_22_3Atrue%257D_2C%257B_22k_22_3A_22Name_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22Concurrent%2520regional%2520operations%2520per%2520project%2520per%2520operation%2520type_5C_22_22_2C_22s_22_3Atrue_2C_22i_22_3A_22displayName_22%257D_2C%257B_22k_22_3A_22_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22region_3Aus-east1_5C_22_22%257D%255D%22,%22s%22:%5B(%22i%22:%22displayName%22,%22s%22:%220%22),(%22i%22:%22currentPercent%22,%22s%22:%221%22),(%22i%22:%22sevenDayPeakPercent%22,%22s%22:%220%22),(%22i%22:%22currentUsage%22,%22s%22:%221%22),(%22i%22:%22sevenDayPeakUsage%22,%22s%22:%220%22),(%22i%22:%22serviceTitle%22,%22s%22:%220%22),(%22i%22:%22displayDimensions%22,%22s%22:%220%22)%5D))Document CIDRS
Section titled “Document CIDRS”- Register unique CIDRs for ephemeral runner projects in the Runbooks
- :warning: If you’re creating a new CIDR block, make sure you add it to the Global allow list.
- In the Admin interface:
Settings -> General -> Visibility and access controls. - If this is missed, we risk running into incidents like this one.
- In the Admin interface:
Define GCP projects in terraform
Section titled “Define GCP projects in terraform”reference issue reference docs
Create the projects for the ephemeral VMs in the config-mgmt repo. Each runner manager will point to one of the projects created here.
- Add a new module in environments/env-projects/saas-runners.tf
- Add the shard name to atlantis.yaml
- Confirm projects exist
- May require an SRE who has permissions to check, as most devs will not have permissions for these projects until the configuration step below when we grant permissions.
Configure GCP projects in terraform
Section titled “Configure GCP projects in terraform”- Run
make new-environment env=my-new-env - Run
make generate-ci-config. (This will auto-generate everything in.gitlab/ci) - Create a new shard entry under
ephemeral_project_networksin environments/ci/variables.tf - Peer the new shard’s network with GPRD under
ci-gateway-network-peersin environments/gprd/variables.tf - Add the CIDRs under
ci-gateway-allow-runnersin environments/gprd/main.tf (using values set in the Document CIDRs step above) - Add a new directory with the shard name in
environments/- This will contain the configuration for each GCP project. If we are adding a shard that is similar to another (e.g.
2XLwhen we already haveXL), copy the pre-existing shard and modify configuration as needed.
- This will contain the configuration for each GCP project. If we are adding a shard that is similar to another (e.g.
- At the root of
config-mgmt, runterraform fmt -recursive - Submit an MR with your changes.
Add chef-repo configs
Section titled “Add chef-repo configs”Add the chef configs for the new runner shard. This will associate with config.toml settings on the runner managers, as well as some other settings (secrets config, analytics, etc).
- Add a config for the global settings of the shard in
roles/,shard-name.json - Add a config for the global
greensettings of the shard inroles/,shard-name-green.json - Add a config for the global
bluesettings of the shard inroles/,shard-name-blue.json - For each runner manager add a
jsonfile for bothgreenandbluerunners:shard-name-green-1.jsonshard-name-blue-1.json- continue numerically for each runner manager
Note: initial concurrent setting should be 0 until we are ready to enable the runners
Add secrets to vault
Section titled “Add secrets to vault”- Add secrets in vault, which will reflect what similar runners have in this location.
Add projects to deployer
Section titled “Add projects to deployer”In the deployer repo:
- add the new shard name in
bin/ci
Run chef-client on runner managers
Section titled “Run chef-client on runner managers”Note: will need chef server admin user and secrets in vault!
:warning: Ensure concurrent settings for any runners is set to 0.
In #production Slack channel, initiate a chef run on the new machines:
# /runner run chef <new shard name> green/runner run chef saas-linux-2xlarge-amd64 green/runner run chef saas-linux-2xlarge-amd64 blueSet up TLS for each runner manager
Section titled “Set up TLS for each runner manager”In #production Slack channel, initiate a tls-certificate test on the new machines:
# /runner run ensure-tls-certificate <new shard name> green/runner run ensure-tls-certificate saas-linux-2xlarge-amd64 green/runner run ensure-tls-certificate saas-linux-2xlarge-amd64 blueIf the run fails for any of the machines, manually ssh into it, and attempt running the /tmp/create-machine.sh and the /tmp/test-machine.sh to find out the root cause.
export VM_MACHINE=docker-machine-tls-test-vm-01/tmp/create-machine.sh && /tmp/test-machine.shDon’t forget to remove any machines you manually created
Section titled “Don’t forget to remove any machines you manually created”docker-machine rm -f $VM_MACHINE
Add projects to cleaner
Section titled “Add projects to cleaner”In the infra-mgmt repo:
- add project names to
run.sh - add project names to
data/gcp/impersonated-accounts.yaml
Define cost factor
Section titled “Define cost factor”Raise concurrent levels
Section titled “Raise concurrent levels”- Update the
default_attributes.cookbook-gitlab-runner.global_config.concurrentvalue to match max capacity in the json file for the entire shard in chef-repo.
Enable the runners on the new shard
Section titled “Enable the runners on the new shard”:warning: Ensure concurrent settings for the runners are production ready, usually set to 1200.
In #production Slack channel, initiate a start run on one fleet:
/runner run start saas-linux-2xlarge-amd64 greenAfter ensuring the runner process is up, enable the new runner-manager VMs through a GitLab Admin account:
-
Login as an Admin.
-
Go to the admin console
-
Filter using the shard’s tag, for example:
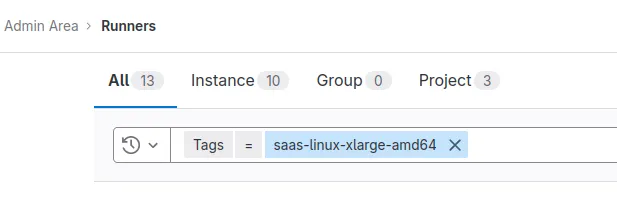
-
Click the play button to enable each of the new machines.
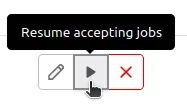
Unpause the new runners in GPRD
Section titled “Unpause the new runners in GPRD”- In the gitlab admin account, unpause the runners (only needs to be done once)