component_saturation_slo_out_of_bounds:gcp_quota_limit
Overview
Section titled “Overview”This alert fires when a resource is nearing it’s allocated quota in GCP for a given project. When a given quota is reached, we may lose the ability to provision additional resources of that type. In GCP, there are two types of constraints to be aware of that can govern the amount of resources that we are able to provision: Quotas and system limits. Quotas are more flexible, and adjustments can be requested through GCP support, limits are static and cannot be increased. This alert only covers quotas.
Most commonly, this alert will fire when additional resources are being provisioned that push resource utilization close to the existing quota. Less commonly, a quota adjustment may have been made to reduce the maximum allocatable resources.
Almost every resource we provision will have a quota associated with it, depending on the particular resource in question the impacts of reaching the limit could impact every service we operate.
When this alert fires, we should look at the resource and GCP project in question, and identify if utilization has been increasing steadily, or if there is an anomalous spike. If usage appears normal, we should engage with GCP support and request a quota increase.
Services
Section titled “Services”Because quotas are applicable to all resources deployed in a given project, it may be difficult to understand exactly which services are the cause, or are being impacted by a quota being reached. Systems that have a higher rate of resource churn are more likely to be impacted by and contribute to quota exhaustion, some of these may include:
- Kubernetes node pools
- ci-runners
Refer to the service catalog to identify the team that owns a particular service when it’s believed to be relevant to this alert firing.
Metrics
Section titled “Metrics”The metrics used in this alert are exported via the GCP Quota Exporter. Exporter configuration and deployment information can be found in ArgoCD repository.
- Quota saturation is calculated as quota utilization / quota limit. The SLO for these metrics can be found here, we currently alert when saturation crosses the 90% threshold.
- You can view these raw metrics in Grafana Explore
- Under normal circumstances we do not expect utilization to go above 90%, if we are crossing this threshold on a regular basis, it is advisable to request a quota increase, or determine where the resources are being used, and reduce utilization.
- This is an example of an alert condition (in GSTG) that likely warrants investigation.
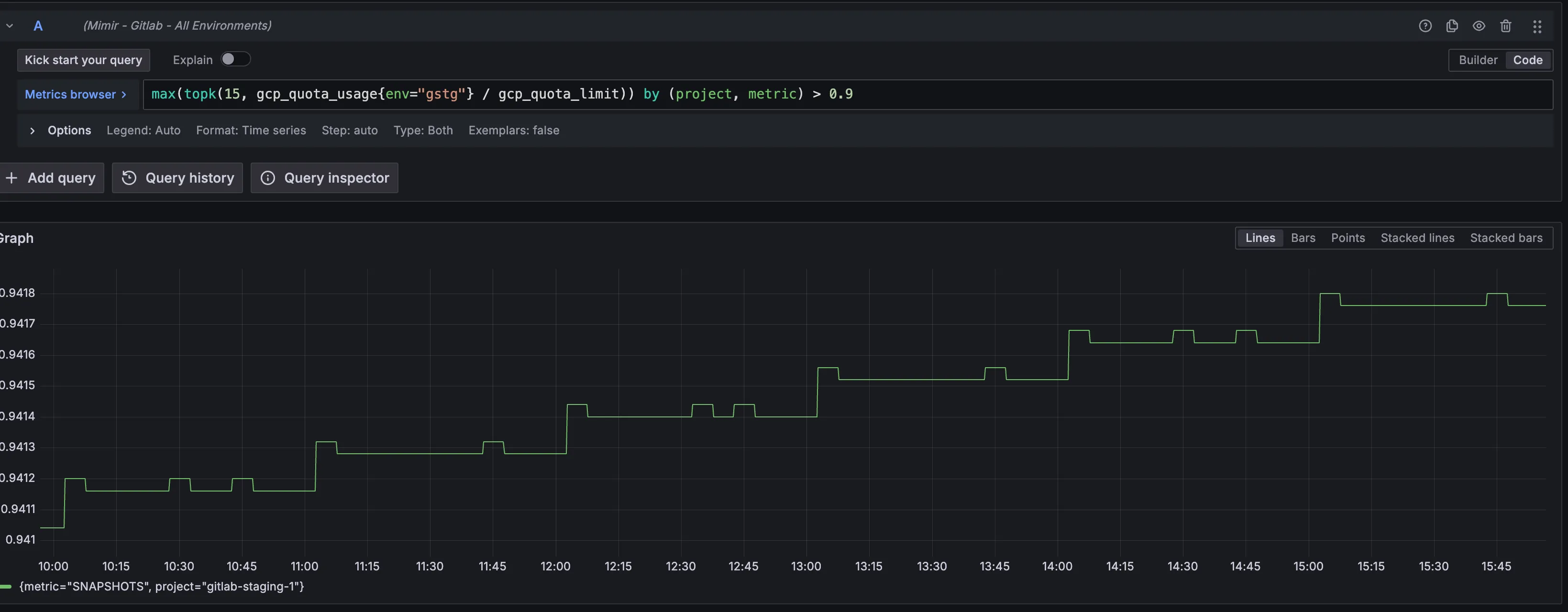
Alert Behavior
Section titled “Alert Behavior”- When this alert fires, it may be necessary to create a silence while engaging with GCP support. Most quota increase requests are handled in ~24 hours, so creating a silence for that amount of time is reasonable after opening a support case.
Severities
Section titled “Severities”Depending on how close to the quota limit we are, and the specific quota in question, the severity may differ significantly. An example of an alert condition that could have customer facing impacts, and thus could be considered S2 severity:
- Quota N2D_CPUS hitting 100% in a GPRD project, which would prevent creation of runner instances or additional capacity to handle customer requests.
And an example condition that is less likely to directly impact customers, and may be considered S3 severity:
- Quota SNAPSHOTS being reached may prevent timely backups from being taken of instances.
Verification
Section titled “Verification”- View the Quota in the GCP console to confirm accuracy of the Prometheus alert.
- Grafana Dashboard
Recent changes
Section titled “Recent changes”- You can view Quota increase requests for a given project in the GCP console
- Check for recent changes in the config-mgmt repository to see if additional resources have been recently provisioned in the project.
Troubleshooting
Section titled “Troubleshooting”- Basic troubleshooting steps:
- Validate that the alert condition is accurate for the resource using the GCP console.
- Determine whether utilization has been steadily increasing, or if the alert is the result of a spike.
- The mechanism to do this will vary depending on the resource type, but a few things to check might be:
- Traffic throughput. Unusually high traffic (perhaps from a DDoS attack) can cause instance groups and node pools to scale up and saturate quota limits.
- ci-runner saturation
- The mechanism to do this will vary depending on the resource type, but a few things to check might be:
- If utilization has been climbing gradually, submit a quota increase request, and consider creating a silence for the alert while the request is being processed if it is not approved immediately.
Possible Resolutions
Section titled “Possible Resolutions”- Previous occurrences of this alert that have been resolved:
Dependencies
Section titled “Dependencies”- The only dependencies for this alert are on the GCP Quota Exporter that is deployed in Kubernetes.
Escalation
Section titled “Escalation”- Escalation to Google support is likely to be needed if resource usage growth is organic.
- You can reach out in
#production_engineeringin Slack if it is unclear where the resource utilization increase is coming from.
Definitions
Section titled “Definitions”- Libsonnet alert definition
- Link to edit this playbook
- Update the template used to format this playbook