Primary Database Node WAL Generation Saturation Analysis
Why do we need this alert?
Section titled “Why do we need this alert?”The goal of these alert is is to let us know that there was spike in amount of WAL generated on the primary database node, so we can investigate while we still have logs available and before the situation gets worse. The alert triggers when WAL generation is over three standard deviations above average, or when it is above 150 MiB/s.
High WAL Generation could be caused by many things; query pattern changes, processes modifying large amounts of data, database maintenance etc. Also this is a saturation metric which we will slowly tip toe up to over time, and without other invention this alert will page more frequently as we run out of headroom.
High WAL Generation is sign of an impending saturation limit with WAL Reciever and/or WAL apply. We theorize that at 150 MB/s (over [5m]) WAL Generation the replicas will not be able to recieve and apply the data fast enough to keep up with generation leading to saturation-induced replication lag.
Replication lag means the data on the replicas will be stale compared to the data on the primaries. This could lead to the loadbalancer keeping sticky reads on the primary longer (more load on primary) or if the replication lag gets older than 2 minutes the loadbalancer will redirect all read traffic to primary (even more load on primary). Finally, there could be data loss if an unexpected failover was to occur. It is also worth noting that on the replicas both CPU and disk IO increases with WAL Generation rate, regardless of the content of that WAL data.
We should investigate what could have caused the WAL spike, and whether the spike is a early warning sign of an impending saturation limit with WAL Reciever and/or WAL apply.
To confirm the spike:
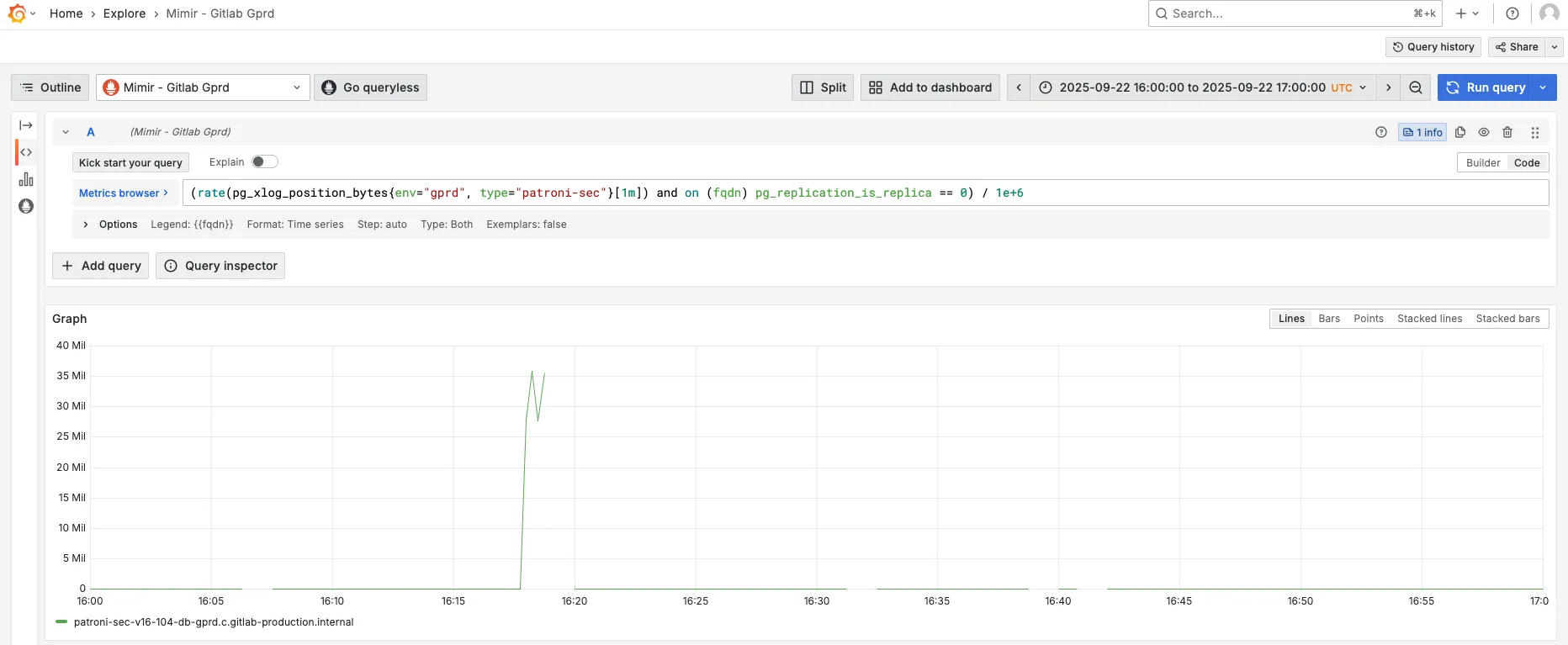
Look at the pg_xlog_position_bytes metric:
rate(pg_xlog_position_bytes{env="gprd", type="patroni"}[1m]) and on (fqdn) pg_replication_is_replica == 0- Go to Mimir.
- For the
cidatabase change thetypelabel topatroni-ci, forsecchange it topatroni-sec. - Adjust time range to 30 minutes before and after the alert.
- In the example bellow we can see a spike in WAL genration at 16:20.
Create an issue
Section titled “Create an issue”Capture all findings in an issue:
- Click here
- Title: YYYY-MM-DD HH:MM: WAL generation spike on the primary node for (main|ci|sec) database
- Labels: TBD
- Assignees: TBD
- Description: Include any relevant information that is available. When referencing to sources like Mimir and Kibana, please include both screenshot and sharable link to the source (example).
How to identify the root cause?
Section titled “How to identify the root cause?”Spikes in WAL generation are often caused by specific queries that produce too much WAL.
WAL bytes / WAL FPI
Section titled “WAL bytes / WAL FPI”To find the top 15 statements by generated WAL:
topk(15, sum by (queryid) ( rate(pg_stat_statements_wal_bytes{env="gprd", type="patroni", queryid!="-1"}[1m]) and on (instance) pg_replication_is_replica == 0 ))
topk(15, sum by (queryid) ( rate(pg_stat_statements_wal_fpi{env="gprd", type="patroni", queryid!="-1"}[1m]) and on (instance) pg_replication_is_replica == 0 ))- Go to Mimir.
- For the
cidatabase change thetypelabel topatroni-ci, forsecchange it topatroni-sec. - Adjust time range to 15 minutes before and after the alert.
- On the graph, click “Show all” so that all series are rendered.
- Look for any statement(s) that stand out.
Other resources
Section titled “Other resources”Other possible causes
Section titled “Other possible causes”- TODO
Map queryid to SQL
Section titled “Map queryid to SQL”To find the normalized SQL for given queryid, follow the mapping docs. Usually searching the logs is enough:
- Go to Kibana.
- Update the filter and set the queryid.
- If needed increase the time range.