Loading StackDriver(SD) Archives from Google Cloud Storage (GCS) into BiqQuery
Summary
Section titled “Summary”Currently searching older logs requires loading line-delimited archive JSON files stored in GCS into another tool; for this we can use Google’s BigQuery(BQ). In order to load a BQ table from a SD produced log archive stored in GCS a dataset must be defined, a table created and data imported through a job using a JSON schema.
- You need to query logs older than 7 days and thus are no longer in our ELK instance.
- You need to query logs older than 30 days and thus are no longer in our SD.
- You need aggregate operators, summarized reports or output visualizations.
Logs that come in to SD (see logging.md) are also sent
to the GCS bucket gitlab-${env}-logging-archive in batches using an export
sink. After 30 days, the log messages are expired in SD, but remain in GCS.
Additionally, because SD exports all Kubernetes container logs mixed
together into stdout/ and stderr/ folders, making it difficult to filter
per container name, vector-archiver
exports to the same GCS bucket the logs sent to PubSub by
fluentd-elasticsearch into a separate folder per PubSub topic under the
folder gke/.
Using the UI
Section titled “Using the UI”These instructions are similar in both the new style (within console.cloud.google.com)
and the old style (external page), but the screenshots may appear with
differing styles.
-
Create a dataset if necessary to group related tables.
-
Click on the dataset’s
...menu to “Create table”. -
Choose “Google Cloud Storage” with “JSONL (Newline delimited JSON)” as the
Source data. -
Using the browse functionality to find an appropriate bucket is not always an option, as only buckets in the same project are listed and data is usually imported from, for example,
gitlab-productionorgitlab-internal. Go to the “Google Cloud Storage” browser, browse the GCS bucketgitlab-${env}-logging-archiveand locate the logs you want to query:- for GKE container logs, look under the
gke/folder - for any other logs, look under the other folders
- for GKE container logs, look under the
-
Insert the bucket path as follows:
bucket/folder/folder/myfile.jsonfor a single file orbucket/folder/folder/*.jsonfor all files in that folder and its subfolders. When using hive partitioning with GKE container logs (see next step), adddt=to the prefix to filter out older path that don’t match, for examplegitlab-gprd-logging-archive/gke/something/dt=*.json.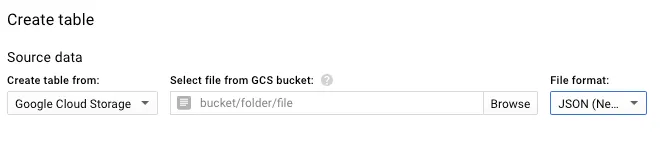
-
The GKE container logs are stored in folders like
dt=YYYY-MM-DDallowing the use of hive partitioning which greatly improves query performances. For this, enableSource Data Partitioningand setSource URI Prefixto the prefix of the path set above (everything before the wildcard) prefixed bygs://and followed by{dt:DATE}to set the partition type, for examplegs://gitlab-gprd-logging-archive/gke/something/{dt:DATE}. Below this field, setPartition Inference Modeto “Provide my own”. -
In the destination section, set the desired table name.
-
When using hive partitioning with GKE container logs, consider setting
Table typeto “External table”, this will allow BigQuery to load files dynamically as needed into a temporary table during queries, saving costs and time. -
Unselect “Auto detect Schema and input parameters” if selected.
-
Use one of our predifined schemas or do it manually adding records for fields, using
RECORDtype for nested fields and adding subfields using the+on the parent record. It should look something like this: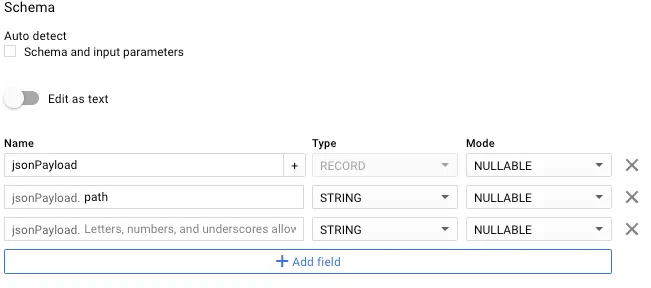
-
In
Advanced options, checkUnknown values -
If the data to be imported is large, consider whether partioning will be necessary. In
Partitioning, select the field on which to partition the data (aTIMESTAMP, typically). Only fields from the schema will be considered.
-
Create the table. If everything is right, a background job will run to load the data into the new table. This usually takes a while, be patient or check the status of the created job under “Job History”.
Alternative: Starting from an existing schema
Section titled “Alternative: Starting from an existing schema”To save time and increase usability, the text version of a table schema can be
dumped with the bq command-line tool as follows:
bq show --schema --format=prettyjson myproject:myhaproxy.haproxy > haproxy_schema.jsonThe result can be copied and pasted into BQ by selecting Edit as text when creating a table that relies on a similar schema.
Contribute changes or new schemas back to logging_bigquery_schemas.
Accessing fields that can’t be loaded due to invalid characters
Section titled “Accessing fields that can’t be loaded due to invalid characters”BigQuery doesn’t allow loading fields that contain dots in their names.
For instance, a field called grpc.method cannot be expressed in the
schema in a way that BigQuery will load it. To work around that, we can
do the following:
-
Load the JSON data as CSV into a table as a single column, giving a fake delimiter that doesn’t appear anywhere in the JSON itself (here we choose ±):
Terminal window bq --project_id "$GCP_PROJECT" \load \--source_format=CSV \--field_delimiter "±" \--max_bad_records 100 \--replace \--ignore_unknown_values \${WORKSPACE}.${TABLE_NAME}_pre \gs://gitlab-gprd-logging-archive/${DIRECTORY}/* \json:STRING -
Transform that data and load into the desired table using
JSON_EXTRACT:Terminal window read -r -d '' query <<EOF || trueCREATE OR REPLACE TABLE \`gitlab-production.${WORKSPACE}.${TABLE_NAME}\` ASSELECTPARSE_TIMESTAMP("%FT%H:%M:%E*SZ", JSON_EXTRACT_SCALAR(json, "$.timestamp")) as timestamp,JSON_EXTRACT_SCALAR(json, "$.jsonPayload['path']") as path,JSON_EXTRACT_SCALAR(json, "$.jsonPayload['ua']") as ua,JSON_EXTRACT_SCALAR(json, "$.jsonPayload['route']") as route,CAST(JSON_EXTRACT_SCALAR(json, "$.jsonPayload['status']") as INT64) as statusFROM \`gitlab-production.${WORKSPACE}.${TABLE_NAME}_pre\`EOFbq --project_id "$GCP_PROJECT" query --nouse_legacy_sql "$query" -
The table with the
_presuffix can now be deleted.
Example Queries
Section titled “Example Queries”The following sample queries can be run on tables created for logs coming from gitlab-gprd-logging-archive/rails-application/* and conforming to the rails_application production schema.
Find the most used Source-IP-Addresses for a User
Section titled “Find the most used Source-IP-Addresses for a User”select jsonPayload.remote_ip, count(jsonPayload.remote_ip) as count from dataset.table where jsonPayload.username='SomeUsername' group by jsonPayload.remote_ipFind Actions by User and respective Paths Performed from a given IP-Address
Section titled “Find Actions by User and respective Paths Performed from a given IP-Address”select jsonPayload.action, jsonPayload.username, jsonPayload.path from dataset.table where jsonPayload.remote_ip='SomeIPAdress' and jsonPayload.username='SomeUsername'Count the Number of Repositories a User has Archived and Downloaded
Section titled “Count the Number of Repositories a User has Archived and Downloaded”select count(jsonPayload.path) as count from dataset.table where jsonPayload.username like 'SomeUsername' and jsonPayload.action = 'archive'- It’s probably possible to perform the above tasks with the
bqcommand line.