Sidekiq SLIs
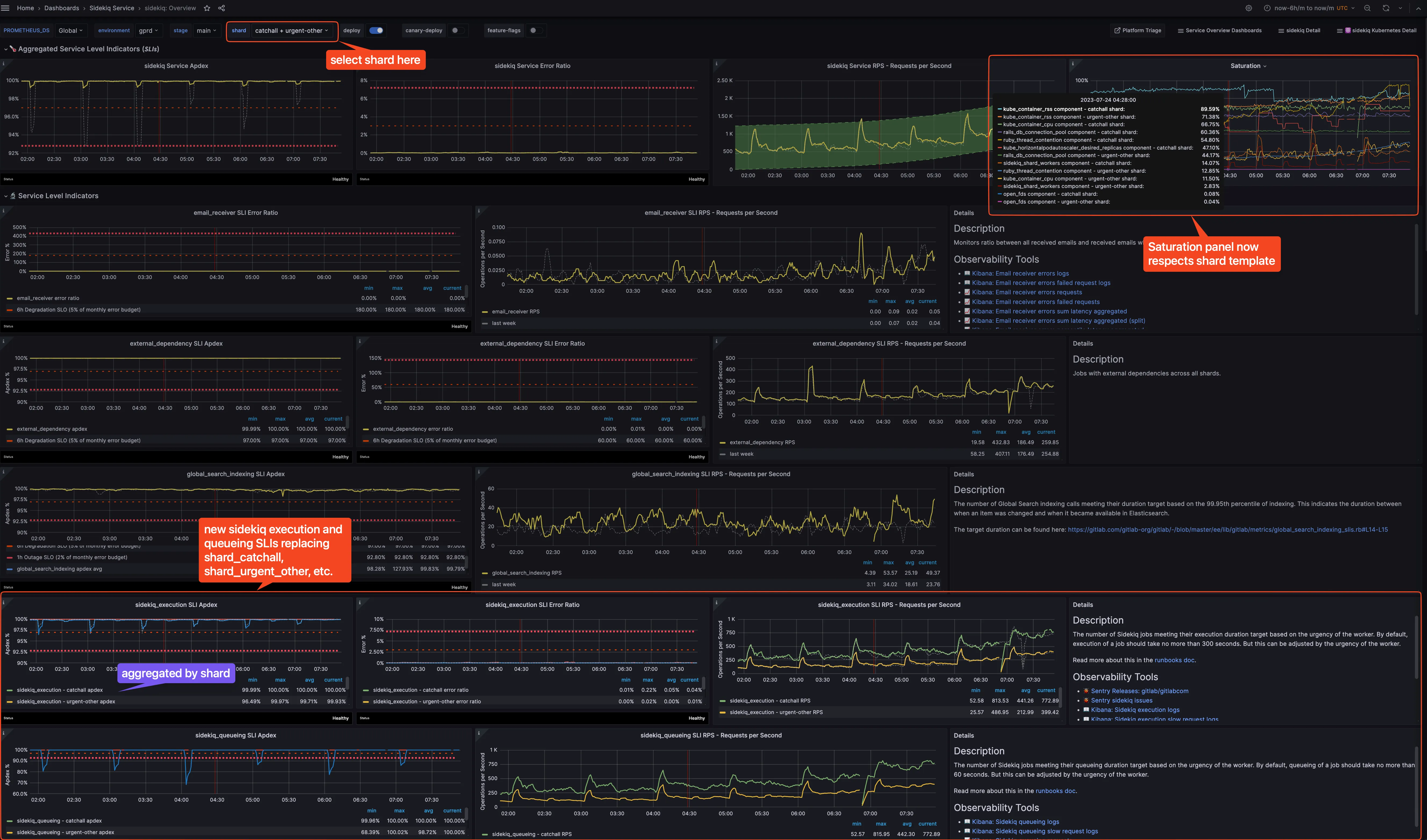
In the past, Sidekiq SLIs exist in the form of SLI per-shard (e.g. shard_catchall, shard_urgent_other, etc). These SLIs combine both execution and queueing (duration that a job was queued before being executed) into a single apdex per shard. Therefore, when a particular shard’s apdex is not performing well, we couldn’t pinpoint whether it’s an execution or queueing problem. On the other hand, we could see the apdex meeting the SLO target, but in reality the real queueing apdex is not meeting the target because execution apdex is still meeting the target.
As part of the works in epic 700, we re-organized SLI per-shard into sidekiq_execution and sidekiq_queueing SLIs (which are aggregated by shard label).
This allows us to surface issues, monitor, and alert on execution and queueing SLIs separately.
The sidekiq_execution and sidekiq_queueing SLIs are defined as Application SLIs.
These SLIs use counter-based metrics to measure a successful apdex measurement in place of the former histogram-based duration metrics.
Observability
Section titled “Observability”The SLIs appear in the Sidekiq Overview dashboard with the shard template.
Ownership
Section titled “Ownership”The execution SLI is owned by stage groups, whereas queueing SLI is owned by Infrastructure.
Apdex measurement
Section titled “Apdex measurement”A successful apdex measurement has to meet the target duration based on the job urgency from the worker attributes.
These apdex measurements happen entirely in the Rails app.
Refer to the requirement in the job urgency
docs
and source code in Rails
app.
There is a separate doc about sidekiq_queueing apdex violations