KubernetesClusterZombieProcesses
Overview
Section titled “Overview”Zombie (or defunct) processes can occur on systems when a parent process spawns a child and fails to clean up the process after it finishes executing. When processes are regularly left in this state, it can lead to PID and file handle exhaustion, thread contention, and several other problematic states. It is usually the result of bugs in code that leave processes in this state.
If this alert is firing, we should check the graphs to determine when processes started being left in this state, if the start of leaking processes correlates to a recent deployment, we may consider rolling back the code. We may also want to locate the workload responsible for the leaking processes, and pre-emptively restart these pods to alleviate some of the symptoms associated with the state temporarily.
Services
Section titled “Services”- This alert can apply to any workload running in Kubernetes.
- See the [## Troubleshooting] section for hints on locating the workloads that are contributing to zombie process creation.
- Refer to the service catalog to locate the appropriate service owner once the workload is identified.
Metrics
Section titled “Metrics”- Metric in Grafana Explore
- Some zombie/defunct process churn is normal during day to day operations. The alert requires that the number of zombie processes be greater than 25 on a cluster for 15 minutes or longer before it will fire.
- We should use this metric to detect when these processes are being created but not removed automatically.
- An example of a problematic state:
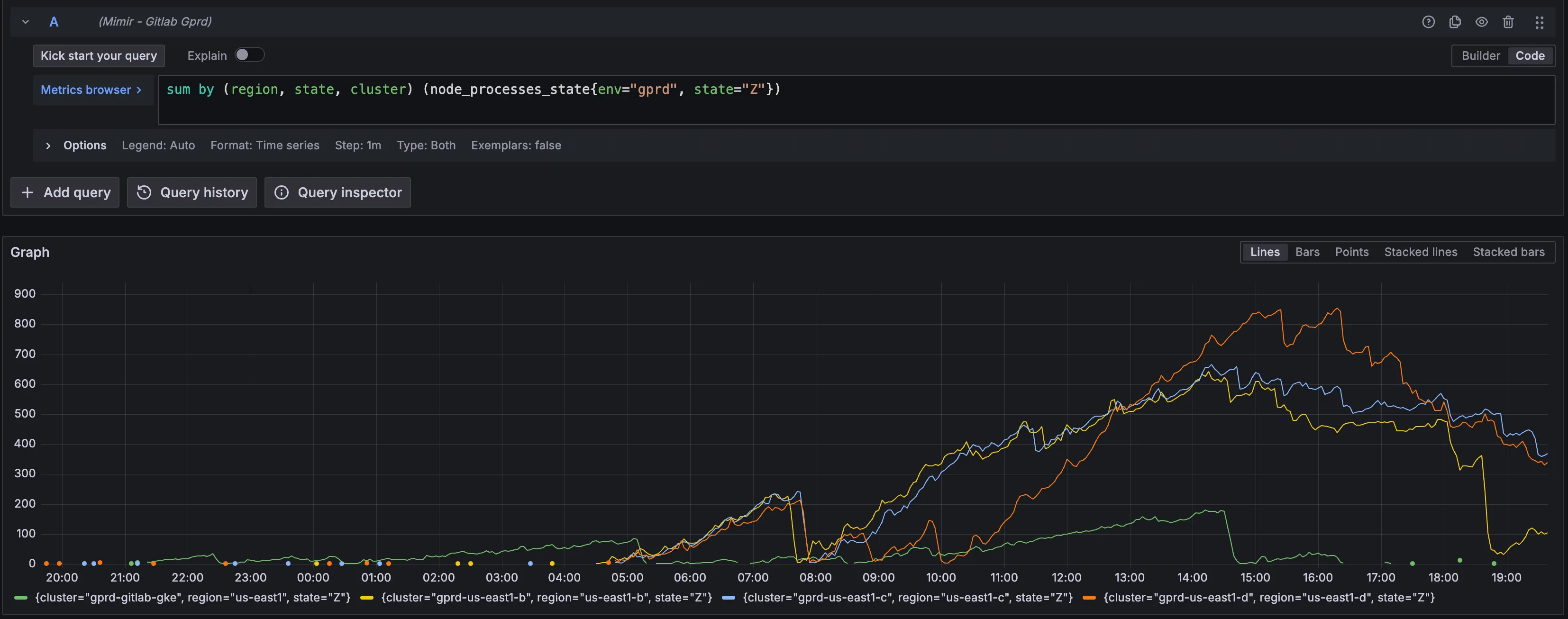
Alert Behavior
Section titled “Alert Behavior”- This alert is intended to capture problems that exist across entire deployments in a given cluster, as opposed to individual workloads. Alerts are aggregated by cluster for this reason. Any created silence has the potential to mask additional new causes of the alert as long as it exists and should be done so for short durations, and with care.
Severities
Section titled “Severities”- This alert will capture symptomatic states of different issues and doesn’t represent an immediate problem on it’s own. Assigning a
S3severity may be appropriate if no additional alerts are firing. - There is a high likelihood that the cause of zombie/defunct processes being spawned will also result in Apdex violations that result in
S2incidents, so this should not be ignored.
Verification
Section titled “Verification”- Refer to the metric in Grafana Explore and verify that the zombie process counts are rising, and not simply the result of a spike that has subsided.
Recent changes
Section titled “Recent changes”- Look for recent deployments to the GPRD environment to determine if recent code changes have been deployed. A rollback may need to be considered if so.
Troubleshooting
Section titled “Troubleshooting”- Attempt to determine the workload that is responsible for spawning zombie/defunct processes.
- Locate a node in the GCP cluster mentioned in the alert that has zombie processes. This can be done by removing the
sum()aggregator. - From the process list (
ps -ef), find any zombie processes as indicated by the<defunct>string. - Use the process name and paths identified to correlate back to the likely workload.
- Locate a node in the GCP cluster mentioned in the alert that has zombie processes. This can be done by removing the
- TODO: We need to document a better way to identify the workload spawning these processes consistently. As of writing, I haven’t found any running systems to create a succinct set of actions to take. The above are just suggestions.
Possible Resolutions
Section titled “Possible Resolutions”-
A recent issue where zombie processes were related to the casue
-
Escalate to the team responsible for the service likely to be spawning the zombie processes.
-
If unsure about the service resulting in the leaked PIDs, escalate to
#g_production_engineering -