`gitalyctl`
Introduction
Section titled “Introduction”gitalyctl implements the solution spec to drain git storages. This is achived by moving all the git repositories from the configured Gitaly storage to different Gitaly storages by use of the woodhouse gitalyctl storage drain so that the drained storages can be decomissioned.
Deployment
Section titled “Deployment”Deployment of gitalyctl is done by through the gitalyctl helm release:
- Create a new GitLab Admin user and a PAT for that user, example.
- Create new
gitalyctl-api-tokenwhich is used bygitalyctlby following the steps in this runbook.gitalyctluses a personal admin credential via the environment variableGITALYCTL_API_TOKENthat allows it to send requests to the Gitlab API. - Add the release to the gitalyctl release helmfile.yaml
How gitalyctl drain storage works
Section titled “How gitalyctl drain storage works”Once woodhouse gitalyctl drain storage is executed the following will happen:
- Drain Group Wikis using GitLab’s API and move the repository to the available Gitaly storage.
- Drain Snippets using GitLab’s API and move the repository to the available Gitaly storage.
- Drain Project Wikis/Repositories using GitLab’s API and move the repository to the available Gitaly storage.
--dry-runthis will only print out the projects that will be migrated, and theirstatistics.repository_size,repository_storagethis allows us to check if we are picking the right projects both for local development and the production deployment.
More details on how this happens can be found in the Gitaly Multi Project solution from step 2
Increase throughput of moves
Section titled “Increase throughput of moves”What is throughput
Section titled “What is throughput”The main metric for throughput is the increase in the number of GB/s we are moving or the number of moves/s. The best metric we have is the Success Rate, the higher it is the faster we are moving repositories
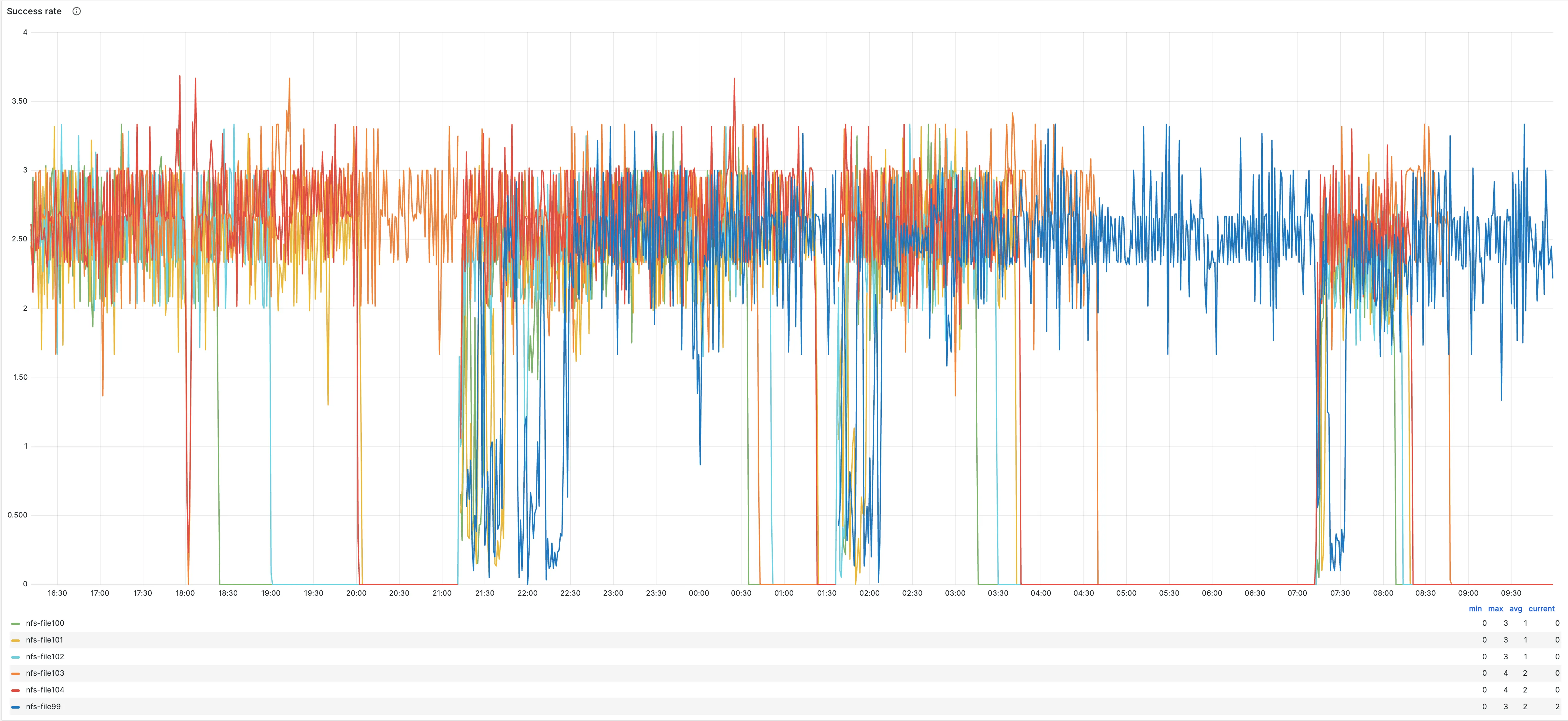
Configuration
Section titled “Configuration”When draining storage there are multiple configuration fields to increase the throughput:
storage.concurrency:- How many storages from the list it will drain in 1 go.
concurrency; Group, Snippet, Project- The higher the value the more concurrent moves it will do.
- The concurrency value is per storage.
move_status_update; Group, Snippet, Project- This is the frequency at which it checks the move status. The faster it checks, the quicker it can free up a slot to schedule a move for another project. We don’t expect this to change a lot currently.
- Look at the precentile to see if we need to reduce this, but it should be well-tuned already.
- Example: https://gitlab.com/gitlab-com/gl-infra/k8s-workloads/gitlab-helmfiles/-/merge_requests/3345#note_1606716477
Bottlenecks
Section titled “Bottlenecks”sidekiq: All of the move jobs run on thegitaly_throttled. This will be the main bottleneck, if you see a largequeue lengthit might be time to scale upmaxReplicas- Risk: One risk of increasing
maxReplicasis that will be increasing the load on the Gitaly servers. So when you increasemaxReplicasmake sure you have enough resource capacity in Gitaly. - Example: https://gitlab.com/gitlab-com/gl-infra/reliability/-/issues/24529#note_1601462542
- Risk: One risk of increasing
gitaly: Both the source and destination storage might end up getting resource saturated, below is a list of resources that get saturated
Stopping migration during emergency
Section titled “Stopping migration during emergency”During migration of gitaly projects from current to new servers, we are perodically moving projects in bulk from old servers (file-*) to new (gitaly-*) servers and that is being done concurrently while new projects are also being created on the same set of available servers. If a migration is not going as expected, we can quickly overrun available disk space and soon be unable to create new projects for customers.
We can determine if there is an ongoing migration by seeing an uptrend in Repository on new Gitaly VMs here
To stop migrations in emergency situation, run:
(gitalyctl is running in ops cluster)
glsh kube use-cluster opsThen in a separate session/window, scale down the replicas to zero:
kubectl scale deployment gitalyctl-gprd -n gitalyctl --replicas=0And reach out to #wg_disaster-recovery slack channel as a followup, to let the team now.
Note: This will not leave any repositories in a bad state.